
机器学习笔记7——决策树原理与应用
前言:关于决策树的含义这里就不详细解释了,简单来说决策树就是根据数据集的最优特征构造一棵树,再用这棵树来预测新的数据属于哪一类。决策树是一种基本的分类算法。(实际上也可以用于回归,这里不做讨论)
构造决策树的算法
一般构建决策树的算法有三种:ID3,C4.5,CART。此三种算法的区别在于:
ID3:特征划分基于信息增益。ID3 仅仅适用于分类问题;ID3 仅仅能够处理离散属性。
C4.5:特征划分基于信息增益比。可以处理连续值。
CART:特征划分基于基尼系数。并且CART算法只能构造出二叉树。CART 既可以用于分类问题,也可以用于回归问题。
信息增益与信息增益比
熵
简单来说,在这里熵是用来衡量数据集纯净度的。熵的值越小,代表数据集纯净度越高。反之,熵越大代表数据集越混乱。
熵的计算公式为:
\(H = -\sum_{i=1}^np(x_i)log_2p(x_i)\)
\(x_i\)为第i个分类,\(p(x_i)\)为选择该分类的概率。
经验熵
当上诉的\(p(x_i)\)(即选则某一类的概率)是由数据估计(特别是最大似然估计)得到时,此时的熵被称为经验熵。举个例子:
| 类别 | 个数 |
|---|---|
| A | 4 |
| B | 6 |
如果\(p(A) = \frac 4 {10},P(B) = \frac 6 {10}\),那么此时算出的熵就是经验熵。
经验熵的公式可以写为:
\(H(D) = -\sum_{k=1}^n \frac {|c_k|}{|D|}log_2\frac {|c_k|}{|D|}\)
使用上式可算出例中的经验熵\(H(D)\)为:
$H(D) = -log_2-log_2 = 0.971 $
条件熵
条件熵\(H(Y|X)\)表示在已知随机变量\(X\)的条件下,随机变量\(Y\)的不确定性。
公式:
\[ \begin{split} H(Y|X) &= \sum_{i=1}^nP(x_i)H(Y|X = x_i)\\&= -\sum_{i=1}^nP(x_i)\sum_{j=1}^mP(y_i|x_i)log_2P(y_i|x_i)\\&= -\sum_{i=1}^n\sum_{j=1}^mP(x_i,y_j)log_2P(y_j|x_i) \end{split} \]
这个条件熵,可能最开始不太好理解,建议参考这篇文章,里面有详细的说明和例题,这里就不举例了。通俗理解条件熵_AI_盲的博客-CSDN博客_条件熵
经验熵对应的条件熵为经验条件熵,一般我们计算的都是经验条件熵。注:经验条件熵必须会自己手算。
特别的,令\(0log_20 = 0\)。
信息增益
信息增益指知道了某个条件后,事件的不确定性的下降程度。特征A对训练集D的信息增益\(g(D,A)\)被定义为集合D的经验熵\(H(D)\)与给定特征A的条件下的经验条件熵\(H(D|A)\)之差:
\(G(D,A)=H(D)-H(D|A)\)
如果一个特征的信息增益越大,说明使用这个特征划分后的样本集可以拥有更好的纯净度。所以在ID3算法中,每一轮我们会计算每个未使用特征的信息增益,然后选择信息增益最大的那个特征作为划分节点。但是这样会有个问题,假设每个属性中每种类别都只有一个样本,那这样属性信息熵就等于零,根据信息增益就无法选择出有效分类特征。
所以提出了信息增益率作为标准的C4.5算法。
信息增益率
信息增益率\(GainRatio(D,A)\)由信息增益\(G(D,A)\)和分裂信息度量\(SplitInformation(D,A)\)共同定义,公式如下:
\(GainRatio(D,A) = \frac{G(D,A)}{SplitInformation(D,A)}\)
\(SplitInformation(D,A) = -\sum_{i=1}^n\frac{|S_i|}{|S|}log_2\frac{|S_i|}{S}\)
也有人把信息增益率的公式写为:
\(GainRatio(D,A) = \frac{G(D,A)}{H(D)}\),\(H(D)\)为训练集D的经验熵。
需要注意的是,增益率准则对可取值数目较少的属性所有偏好,因此,C4.5算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
关于CART算法和基尼系数
不在这里进行说明,之后可能会单独开一篇文章。
决策树的构建
上面已经介绍了构建决策树需要用到的子模块,即经验熵的计算和最优特征的选择。接下来介绍决策树的整体构建步骤。
构建决策树的核心都是递归算法,结束递归的条件又多种,将在之后的决策树剪枝中介绍。
ID3算法
核心是在各个节点上对应信息增益准则选择特征,递归构建决策树。
具体方法:
从根结点开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征。
由该特征的不同取值建立子节点,再对子结点递归地调用以上方法,构建决策树;直到达到预剪枝条件或没有特征可以选择为止。
得到一个决策树。
C4.5算法
与ID3算法的区别在于将信息增益率作为选择特征的标准。
决策树的剪枝
如果不进行剪枝,那么决策树生成算法递归地产生决策树,直到没有特征选择为止。这样生成的决策树往往会导致过拟合。过拟合在前面的文章已经解释过,这里不再进行说明。为了防止过拟合,我们需要对决策树进行剪枝。
决策树的剪枝分为预剪枝和后剪枝两大类。
预剪枝
预剪枝指在生成决策树的过程中提前停止树的生长。常用的预剪枝有以下几种:
当树到达一定深度的时候,停止树的生长。
当信息增益,增益率和基尼指数增益小于某个阈值的时候不在生长。
达到当前节点的样本数量小于某个阈值的时候。
计算每次分裂对测试集的准确性提升,当小于某个阈值,或不再提升甚至有所下降时,停止生长。
优缺点:
优点:思想简单,算法高效,采用了贪心的思想,适合大规模问题。
缺点:提前停止生长,有可能存在欠拟合的风险。
后剪枝
后剪枝是先从训练集生成一颗完整的决策树,然后自底向上的对决策树进行剪枝。后剪枝一般不常用,这里暂时不拓展。贴一个连接:西瓜书决策树预剪枝后剪枝过程详解_铁锤2号的博客-CSDN博客
缺点:耗时太长。
利用sklearn实现决策树
关于决策树的手动实现:机器学习实战(三)——决策树_呆呆的猫的博客-CSDN博客_决策树
这篇文章写的十分完整,甚至包括决策树的储存与绘图,这里就不贴手动实现的代码了,因为感觉贴了也和他的长得几乎一样?并且文章中还提到了sklearn决策树的各种参数说明,可以说是十分详尽了。不过他代码中注释写错了一些,自己跟着走一遍就看得懂了。
导入并分割数据集
数据集下载:Classifying wine varieties | Kaggle
这个数据集sklearn其实已经内置了,只需要:
1 | import pandas as pd |
输出:
1 | [[1.423e+01 1.710e+00 2.430e+00 ... 1.040e+00 3.920e+00 1.065e+03] |
可以更直观的展示数据集:
1 | # 更直观的展示 |
输出:
1 | 0 1 2 3 4 5 ... 8 9 10 11 12 0 |
分割数据集为训练集和测试集(7:3)
1 | X_train,X_test,y_train,y_test = train_test_split(wine.data,wine.target,train_size=0.7) |
输出:
1 | 0 1 2 3 4 5 ... 8 9 10 11 12 0 |
决策树算法一般不需要标准化,所以这里省去了标准化。
建立并训练决策树
sklearn并没有实现C4.5算法,所以这里用的ID3,所以要用C4.5算法还是需要手动实现。sklearn默认使用的是CART算法(基尼系数)。
1 | dec_tree = tree.DecisionTreeClassifier(criterion='entropy') |
测试决策树
1 | y_predict = dec_tree.predict(X_test) |
输出:
1 | y predict value is:[1 2 1 1 1 1 1 1 0 1 1 0 1 1 2 0 1 2 1 2 1 2 2 0 0 0 0 2 0 1 0 0 1 1 2 0 0 |
使用Graphviz绘制决策树
下载graphviz:Download | Graphviz
配置环境变量:
pip安装graphviz:
1 | !pip install graphviz -i https://pypi.tuna.tsinghua.edu.cn/simple |
然后重启Pycharm,
1 | import graphviz |
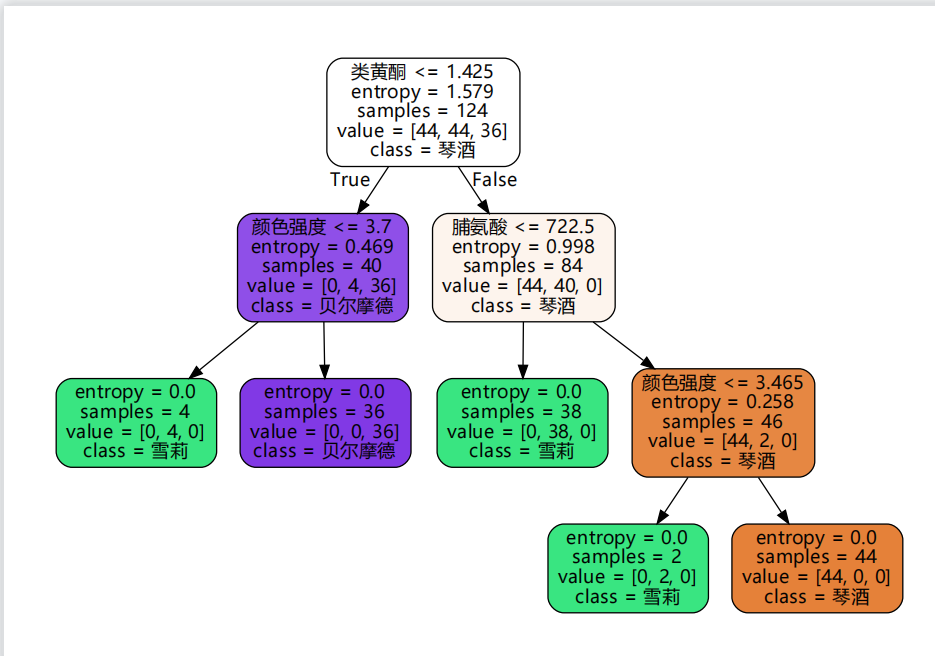
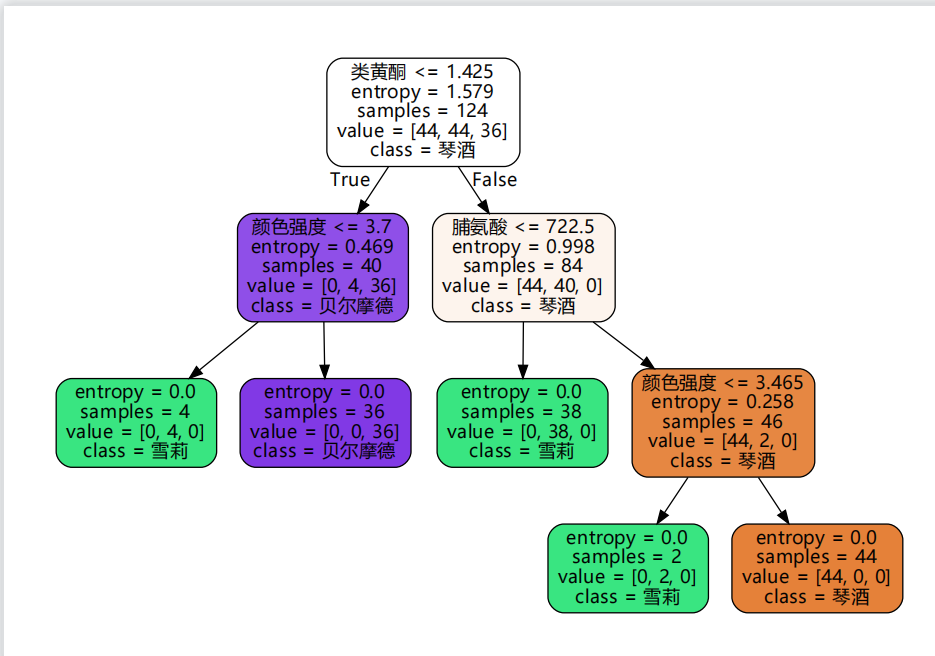
保存和读取决策树
决策树的训练过程往往很浪费时间,所以我们可以把训练好的决策树保存起来方便直接调用。这里介绍模型保存方法,不仅仅适用于决策树,而适用于所有模型。
使用pickle保存模型
存储模型:
1 | import pickle |
新开一个py读取模型并查看模型:
1 | import pickle |
决策树的优缺点
优点:
可以可视化,易于理解
决策树几乎不需要预处理
缺点:
决策树可能会创建一棵过于复杂的树,容易过拟合,需要选择合适的剪枝策略
决策树对训练集十分敏感,哪怕训练集稍微有一点变化,也可能会产生一棵完全不同的决策树。(可以在分割训练集时把随机种子去掉,会发现每次的决策树都不一样)
最后还是贴一个C4.5的实现文章连接吧:python实现C4.5_张##的博客-CSDN博客